DFS(Depth - First search)
깊이 우선탐색이라고도 불리며 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다.

DFS를 알아보기 전에 간단한 그래프를 알아보자
그래프
노드(node) 와 간선(edge)으로 표현된다. 이때 노드를 정점(vertex)이라고도 한다.
위 그림에서 노드1과 노드2는 간선으로 이어져 있다 이때 노드1과 노드2는 인접한다(adjacent)라고 표현한다.
프로그래밍에서 그래프를 표현하기 위해 크게 두가지 방법을 사용한다.
1. 인접행렬(adjacency matrix) : 2차원 배열로 그래프의 연결 방식을 표현하는 방식
2. 인접리스트(adjacency list) : 리스트로 그래프의 연결관계를 표현하는 방식
인접행렬로의 그래프

노드 1과 노드 2는 서로 연결되어 있지 않으므로 X(INF - 무한)으로 표현되고 노드1 과 노드1은 간선의 길이가 0이다.
따라서 (0, 0), (1, 1), (2, 2)는 0이며 (0, 1) = 5, (0, 2) = 3으로 대각선을 기준으로 하여 대칭을 이루는 행렬이 나온다.
이를 파이썬으로 표현하면
# 무한표현
INF = 999999
graph = [
[0, 5, 3],
[5, 0, INF],
[3, INF, 0]
]
print(graph)
2차 행렬로 표현이 가능하다.
인접리스트로의 그래프

노드 0에는 노드1과 5의 간선길이로 연결되어 있고 노드2와 3의 간선길이로 연결되어 있다.
(노드1이 먼저나 노드2가 먼저나 상관없다)
노드 1에는 노드0과 5의 간선길이로 연결
노드 2에는 노드0과 3의 간선길이로 연결
이를 파이썬으로 표현하면
node_num = 3
graph = [[] for _ in range(node_num)]
# 노드 0에는 노드1이 5의 간선길이로 연결
graph[0].append((1, 5))
graph[0].append((2, 3))
# 노드 1
graph[1].append((0, 5))
# 노드 2
graph[2].append((0, 3))
print(graph)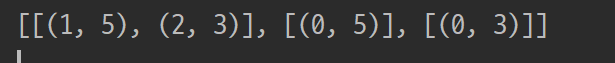
graph[0]에는 2개의 노드가
graph[1]에는 1개의 노드 graph[2]에는 1개의 노드가 간선의 정보와 같이 들어있다.
두개의 차이점은
1. 인접행렬은 대칭되는 정보가 존재하므로 메모리 낭비가 있다.
2. 인접행렬은 노드의 연결 정보를 graph[노드1][노드2]로 간단히 확인 가능하다. 하지만
인접리스트는 노드 0과 관련된 정보를 모두 돌아야 어떻게 연결되었는지 알수있다.
(위 그래프는 양방향 그래프이나, 인접리스트는 양방향 그래프 인지 처음부터 확인이 불가능하기 때문)
DFS는 깊이우선탐색이므로 먼저 root node(위 그래프에서는 노드0)에서
가장 깊은 단계의 노드를 방문한 후 다시 돌아가 다른경로로 탐색하는 알고리즘 이다.
1. 탐색 시작 노드(root node)를 스택에 삽입하고 방문 처리를 한다.
2. 스택의 최상단에 있는 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고
방문 처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단에 있는 노드를 꺼낸다.
3. 2번의 과정을 반복 할 수 없을 때 까지 한다.
일반적으로 인접한 노드중에서 방문하지 않은 노드가 여러개 있으면 번호가 낮은 것부터 처리한다.(관행적 으로)
1. 노드 1부터 탐색을 시작하므로 스택에 1을 삽입하고 방문처리.

2. 노드1에는 방문하지 않은 노드가 2, 3, 8이 있지만 숫자가 낮은 2부터 돈다. 2를 스택에 넣고 방문처리.

3. 노드2에는 방문하지 않은 노드가 7이 있다. 그러므로 7을 스택에 넣고 방문처리.
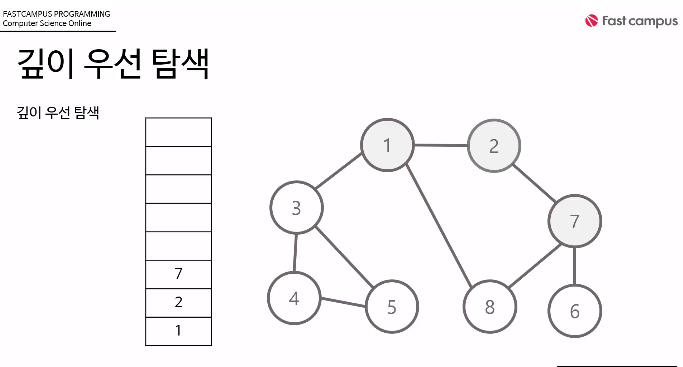
3. 노드 7에는 방문하지 않은 노드가 6, 8 있다 6이 숫자가 낮으므로 스택에 넣고 방문처리.

4. 노드 6은 방문하지 않은 노드가 연결되어 있지 않으므로 스택의 최상단 노드인 6을 뺀다.
5. 스택의 최상단에 있는 노드인 노드7은 방문하지 않은 노드8이 연결되어 있으므로 8을 스택에 넣고 방문처리.

6. 스택의 최상단 노드인 노드8에는 방문처리하지 않은 노드가 연결되어 있지 않으므로 최상단 노드인 8을 스택에서 뺀다.

7. 이를 반복하면 결국 1만 남고 다시 노드1에는 방문하지 않은 노드3 이 이있으므로 스택에 넣고 방문처리.
8. 노드3은 4 ,5가 있으나 숫자가 작은 4부터 스택에 넣고 방문처리.
9. 노드4는 5가 있으므로 스택에 넣고 방문처리
10. 이제 스택은 1 -> 3 -> 4 -> 5 인상태에서 모든 노드가 방문되었으므로 차례로 5, 4, 3, 1 노드 순으로 스택에서
나온다.
결과적으로 노드 탐색순서 (스택에 들어간 순서)는
1->2->7->6->8->3->4->5
이를 파이썬으로 구현하면
node_num = 8 + 1
graph = [[] for _ in range(node_num)]
# 노드 1에는 노드2가 연결
graph[1].append(2)
graph[1].append(3)
graph[1].append(8)
# 노드 2
graph[2].append(1)
graph[2].append(7)
# 노드 3
graph[3].append(1)
graph[3].append(4)
graph[3].append(5)
graph[4].append(3)
graph[4].append(5)
graph[5].append(3)
graph[5].append(4)
graph[6].append(7)
graph[7].append(2)
graph[7].append(6)
graph[7].append(8)
graph[8].append(1)
graph[8].append(7)
print(graph)
stack = []
# 그래프, 시작노드, 방문기록
def dfs(graph, v, visited):
stack.append(v)
visited[v] = True
print(stack)
for i in graph[v]:
if visited[i] == False:
dfs(graph, i, visited)
visited = [False] * node_num
dfs(graph, 1, visited)dfs를 보면 시작부터는 시작노드를 스택에 추가하고 방문표시를 한다.
연결된 노드가 방문이 안되어있으면 dfs 재귀를 불르고 방문이 다되면 그 함수는 끝나며
재귀 윗부분으로 올라간다. 재귀함수가 있는 메모리 스택이 곧 해당 stack이다.
'ComputerScience > 자료구조' 카테고리의 다른 글
| 자료구조 - 트리[이진탐색트리] (0) | 2020.09.21 |
|---|---|
| 자료구조 - 이진탐색 (0) | 2020.09.21 |
| 자료구조 - 정렬 [선택 정렬, 삽입 정렬, 퀵 정렬, 계수 정렬] (0) | 2020.09.04 |
| 자료구조 - 탐색알고리즘 BFS (0) | 2020.08.25 |
| 자료구조 기초 - 탐색, 스택, 큐, 재귀함수 (2) | 2020.08.18 |



